
この記事を読むのに必要な時間は 約7分 です。
前回記事はこちらです👇
https://clshinji.com/【python】pdfのテキストを抽出する<第3回>/140/
今回、作成したアプリ
前回までにスシローさんのアレルギー情報のPDFにある表を、データフレーム形式&CSV形式で取得することが出来ました。
今回は、そのデータを使用して、お店に行ったときに使えるWebアプリを作成していきます。
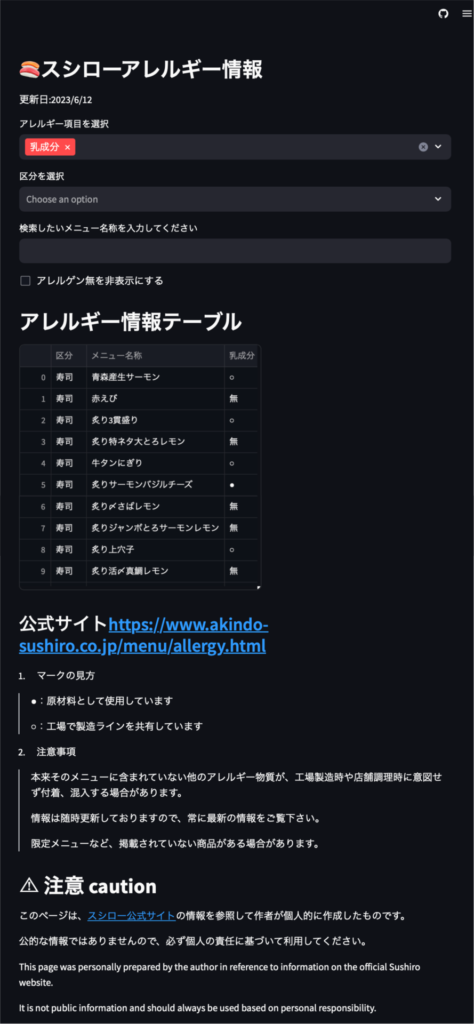
ということで、今回作成したWebアプリがこちらです👇
Streamlitというフレームワークを使用して実装しています。
GitHub上で公開していますので、誰でも使用できる環境になっています。
一方で、あくまで個人的に作成しているアプリなので、自己責任での使用でお願いします。
StreamlitでのWebアプリ開発
今回のWebアプリ実装で使用したStreamlitは、Pythonを用いて比較的簡単にアプリを実装できるフレームワークです。機械学習の分野等でよく用いられているようです。
<公式サイト>Streamlit👉https://streamlit.io
実行用のPythonファイルを準備しておき、以下のようなコードを実行することでWebアプリとして実行できます。
$ Streamlit run main.pymain.pyの中身は、例えばこんな感じです。
import streamlit as st
def main():
st.header('Hello Streamlit')
list = ['a', 'b', 'c', 'd']
st.selectbox('List', list)
if __name__ == '__main__':
main()
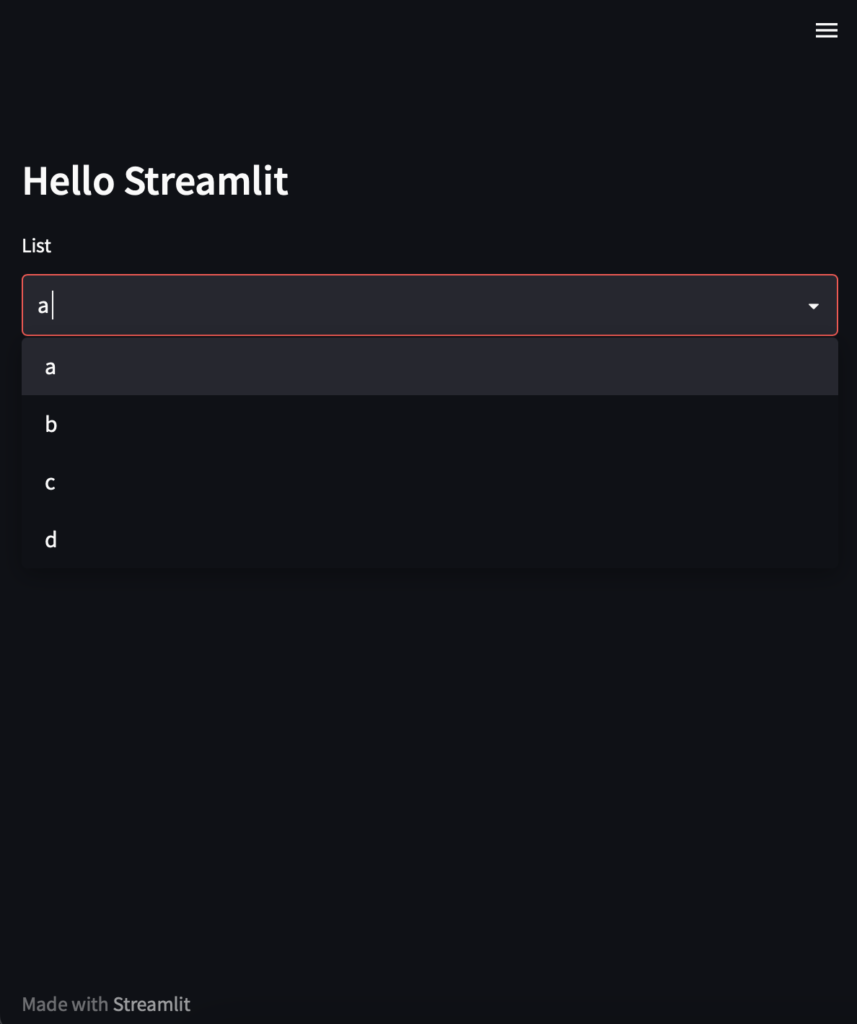
これを実行すると、以下のように表示されます。
タイトルとセレクトボックスだけを置いていますが、非常に簡単に実装できました。
そして、実際に実装したコードがこちらです👇
後述しますが、GitHubにも公開していますので、良かったら見てみてください。
import streamlit as st
from pathlib import Path
import pandas as pd
def main():
'''
スシローHPのアレルギー情報(pdf)から読み取ったテーブルを基にして、アレルギー情報を検索するアプリ
アレルギー情報ファイル名:allergy_table.csv
サイドバーの
'''
csv_path = 'allergy_table.csv'
type_column_name = '区分'
names_column_name = 'メニュー名称'
st.markdown('# 🍣スシローアレルギー情報')
st.write('更新日:2023/6/12')
# データフレームの読み込み
df = pd.read_csv(csv_path, index_col=0)
columns_list = list(df.columns)
class_list = df[type_column_name].unique()
# ユーザ入力
choiced_allergy_list = st.multiselect(
'アレルギー項目を選択',
columns_list[2:],
['乳成分']
)
if not choiced_allergy_list:
st.error('アレルギー項目を選択してください')
choiced_type_list = st.multiselect(
'区分を選択',
class_list,
)
key = st.text_input('検索したいメニュー名称を入力してください')
dropna_check = st.checkbox('アレルゲン無を非表示にする')
# 表示用データフレームの作成
# 選択されたアレルギー項目だけを抽出
if choiced_allergy_list:
drop_columns_list = [x for x in columns_list if x not in choiced_allergy_list and x != type_column_name and x != names_column_name]
else:
drop_columns_list = []
df_view = df.drop(columns=drop_columns_list).copy()
# アレルギーが含まれない行を削除する
if dropna_check:
df_view = df_view.dropna()
# df_viewのNaNを無に置き換える
df_view = df_view.fillna('無')
# 選択した分類だけを抽出する(未選択の場合は実行しない)
if choiced_type_list:
df_view = df_view[df_view[type_column_name].isin(choiced_type_list)]
# 検索keyに部分一致する商品だけを抽出する
df_view = df_view[df_view[names_column_name].str.contains(key)]
# デバック用情報をサイドバーに表示させる
# st.sidebar.write(f'columns_list : {columns_list}')
# st.sidebar.write(f'choiced_allergy_list: {choiced_allergy_list}')
# st.sidebar.write(f'key: {key}')
# st.sidebar.write(f'choiced class: {choiced_type_list}')
# st.sidebar.write(f'drop list: {drop_columns_list}')
# st.sidebar.write('アレルギー項目リスト👇')
# st.sidebar.write(columns_list)
# 結果を表示する
st.markdown('# アレルギー情報テーブル')
st.dataframe(df_view)
# 注意書き
caution_markdown = read_markdown_file("caution.md")
st.markdown(caution_markdown, unsafe_allow_html=True)
return
@st.cache()
def read_markdown_file(markdown_file):
return Path(markdown_file).read_text()
if __name__ == '__main__':
main()
GitHubでのデプロイ(Streamlit Sharing)
大変ありがたいことに、Streamlit Cloud(Streamlit Sharing)というサービスが公開されていますので、こちらを活用してアプリを公開していきます。
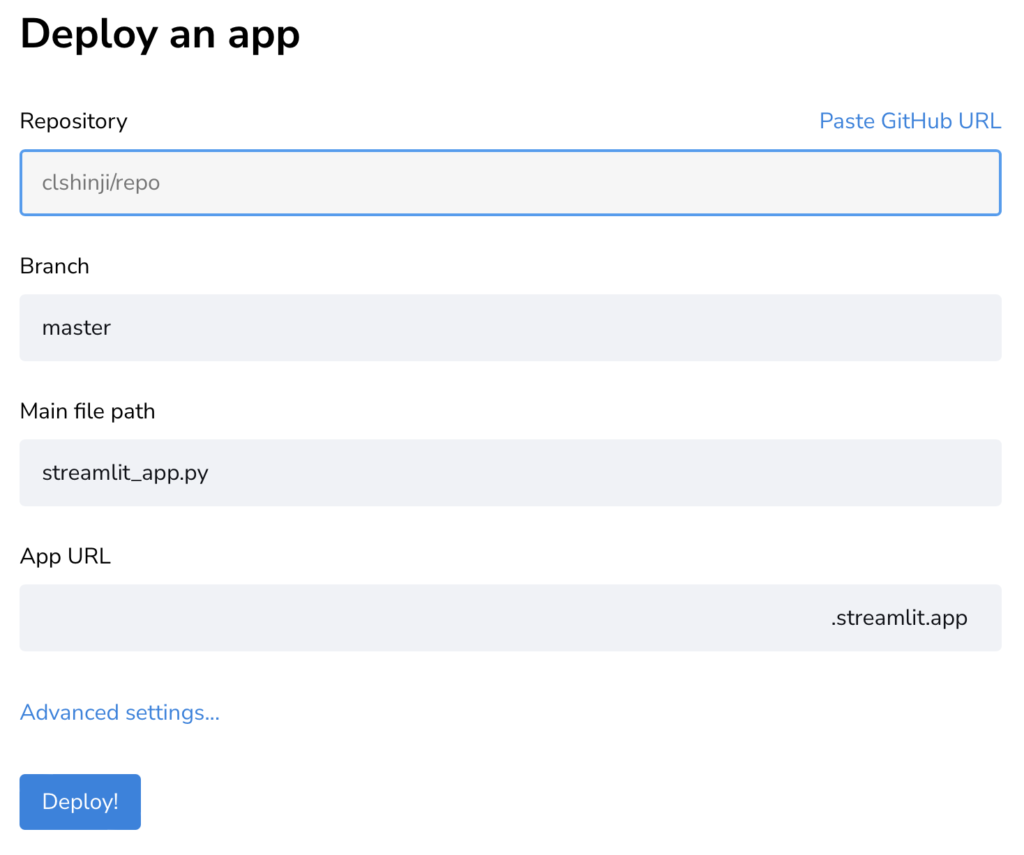
ログイン後に新規アプリを方法はかなりシンプルです。
- GitHubのリポジトリに先程のStreamlit用のファイル一式を格納する
- Streamlit Cloudで以下の項目を選択する
- GitHubのリポジトリ名(例)clshinji/st_apps
- ブランチ名(例)master
- Streamlit用のメインファイル(例)main.py
- アプリのURL ※自動生成?
- 公開完了!
以下の手順を実行することで、簡単にStreamlitで作成したアプリをWeb上に公開することが出来ました。
感想&今後の課題
全4回になりましたが、スシローに行ったときにアレルギー情報をチェックしやすいアプリが完成しました。
当初は、チャットボットが良いかなと思っていましたが、Webアプリでも十分使用できるモノが出来たので、今回は大満足です。
妻にも使ってもらっていますが、大好評です♫
ちなみに、チャットボットの実装については、まだまだ知識&スキルが足りていないので、今後に向けて勉強は続けたいと思います。
ちなみに、今回作成したコードは、とりあえず動けば良いやというクオリティなので、プロの方が見たら、かなりツッコミどころがあるかと思います笑
それに臆せずに、これからもプログラミングのスキルを磨いていきたいと思います!
一方で、現時点では、スシローさんのアレルギー情報が更新された場合は、手動でもう一度PDFデータからCSVを生成しなおさなければなりません…!
今のところは、週末に行くくらいなので、金曜あたりに情報が更新されていないかをチェックするようなルーティンになっています笑
本来はスクレイピングして自動更新するツールにすれば良いのですが、これも今後の課題ですね…笑
さて、次回は何を作ろうかな〜


コメント